Kubernetes, often abbreviated as K8s, originated from Google’s internal project, Borg, and was open-sourced in 2014. It quickly gained popularity as an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. While its roots lie in container orchestration, Kubernetes has evolved into a robust and versatile tool that addresses the complexities of modern cloud-native development.
The widespread adoption of Kubernetes can be attributed to its ability to simplify the deployment and management of applications at scale, offering a consistent and standardized way to handle containerized workloads. Its significance in modern cloud environments stems from the fact that it provides a unified platform for developers, operators, and administrators, fostering collaboration and streamlining the development-to-deployment lifecycle.
In today’s dynamic cloud landscape, Kubernetes has become the de facto standard for container orchestration, enabling organizations to achieve higher levels of efficiency, scalability, and reliability in their applications. Understanding the architecture of Kubernetes is crucial for developers and system administrators as it empowers them to harness the full potential of this powerful tool, facilitating seamless application deployment, resource management, and scalability in complex cloud-native environments.
Source: https://chat.openai.com/
This opened new attack vectors exploited by malicious threat actors and thus led to an increased interest in the topic by blue & red teams, as well as penetration testers and ethical hackers.
In the next sections we will go over a subset of the architecture for a Kubernetes setup. We will explore the different components while mainly focusing on the API server, Namespaces, Service Accounts, nodes and pods. We will also touch slightly on the other components and concepts such as the Kubectl command line utility.
Architecture of a Kubernetes setup
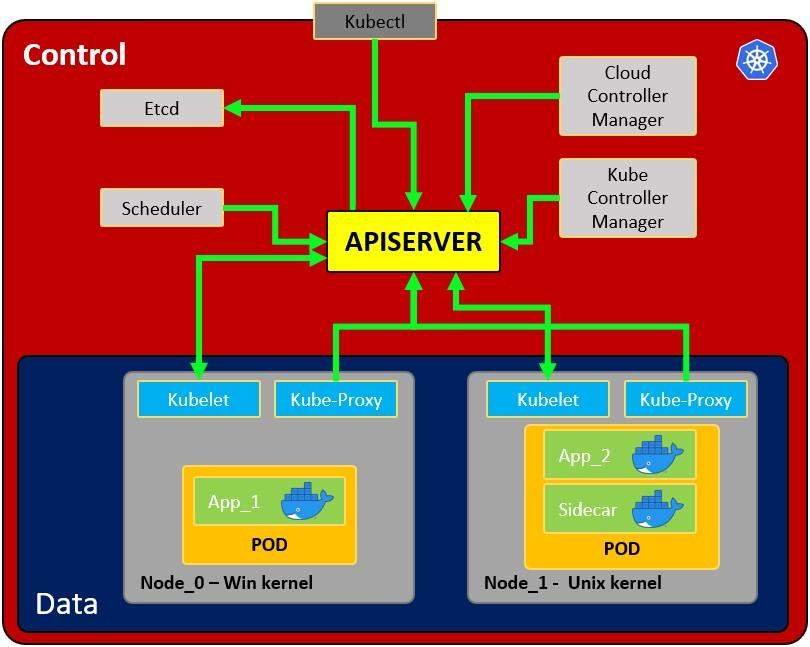
Image source: https://cloud.hacktricks.xyz/pentesting-cloud/kubernetes-security/kubernetes-basics
API Server
The first component we need to talk about is the API server. As we can observe from the figure shown previously it’s the centerpiece of the setup. The API server is the frontend through which all other components interact. It is responsible to configure the data for API objects in the cluster, such as different pods, nodes, services, replication controllers etc.
This will become especially important in later stages such as the enumeration and exploitation of certain misconfigurations or vulnerabilities, as a lot of the communication takes place through the API server.
There are different ways to communicate with the API server from a users perspective. It can be used in a restful manner through HTTP requests or by using the Kubectl binary.
Source: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/
Kubectl
The Kubectl is a binary serving as the command line tool (CLI) to communicate with the API server. There are different ways to obtain this binary depending on the environment that you are currently on. Generally speaking the binary often is used to deploy applications and inspect or manage resources in the Kubernetes cluster. This may for example mean deploying a new container in a pod on a certain node or namespace (more regarding nodes and namespaces later).
Source: https://kubernetes.io/docs/tasks/tools/#kubectl
Although it might not align with LOTL (Living-off-the-land) strategies, it might be very beneficial to upload this binary to any pod or node you have control over to ease up the communication with the API server (if you are not worried about OPSEC too much). You’ll find that some instances already will have this binary installed and ready to go when you land on a pod or node in the cluster. It is also worth noting that, if the API Server is accessible through the internet or network, you may not need to upload the binary to the compromised instance.
Nodes
The next component we need to talk about are nodes. These are running all the services required to run the individual pods on them. The nodes can be virtual or physical machines in the Kubernetes cluster. An analogy for this would be using your physical computer to run virtual machines, which in turn start and run different applications. The physical computer would be the host or node while the vms running on the node represent the pods, these vms would then contain the different applications presenting the containers.
Source: https://kubernetes.io/docs/concepts/architecture/nodes/
Corporate Kubernetes clusters often contain a number of nodes with different pods running under them. Usually when deploying a new pod in a cluster the node with the most resources available will be selected for deployment unless specified otherwise (as far as I know). When obtaining access to a node, this immediately also leads to access to all pods running on that particular node.
Components that a node includes are a kubelet, container runtime and kube-proxy. In this article, we will focus on exploring the kubelet and kube-proxy, while the container runtime will not be covered in detail.
Kubelet
The kubelet is referred to as “node agent” and runs on every node. The kubelet will make sure the pods running under that node are healthy, by making sure they run in line with the specifications set for the individual pod.
Source: https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
This Kubelet API can be directly queried, if you have the IP address of the node, unauthenticated access is configured and the node is accessible from your current network environment, you potentially are able to extract interesting information, create resources or even execute commands on existing ones.
Source: https://kubernetes.io/docs/reference/access-authn-authz/kubelet-authn-authz/
Undocumented paths for the kubelet API server can be found in the open source repository of Kubernetes. We will explore some attacks that can be launched with information from the undocumented sources.
Source: https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/server/server.go
Kube-proxy
The kube-proxy might enforce network rules (on nodes) allowing or denying communication to the pods under that node from the network inside or outside the cluster.
Source: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-proxy/
This might be of relevance when thinking about persistence or data exfiltration techniques or communication with the pods as a whole.
Pods
A Pod serves as a shared environment for one or more containers. Typically, these containers run the actual application with its individual configuration, such as a database or web application. This has the same benefit as standalone docker containers, which is preserving an environment and not interfering with other applications through system wide configuration or shared configuration across multiple apps.
Source: https://kubernetes.io/docs/concepts/workloads/pods/
Gaining access to a pod is a common first foothold you’ll get in a Kubernetes environment. From this stage on you can try to elevate your privileges and potentially break out of the pod (also referred to as pod to node escape). Furthermore, you’ll most likely have access to the environment and application configuration, which might reveal sensitive information to extend your access (not necessarily in relation to Kubernetes).
Namespaces
Even though not shown in the previous diagram, as namespaces were mentioned during the article, a quick primer to what they are: A namespace is nothing more than a logical separation and isolation of resources within the Kubernetes cluster.
You’ll find that different resources (such as pods) are part of different namespaces. This becomes important when it comes to permissions, as service accounts might only have access to a subset of namespaces (e.g. the service account of a pod might only have access to its current namespace).
Source: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
Service Accounts
Adding onto namespaces, service accounts are used by pods to authenticate with a specific set of permissions to the Kubernetes API. Depending on the permissions set for these service accounts, they might have access to additional resources in the cluster or are even used by other pods or resources. Each service account has a token associated with them and uses this token as an authentication method to communicate with the API server.
Sources:
You’ll often find yourself searching for these service account tokens (from an offensive security perspective) and use them to authenticate to the Kubernetes API, to further enumerate your current permissions on the cluster. There can be interesting permissions set, that could for example allow you to query the secrets of the cluster, create your own resources or simply obtain more information (such as existing pods, namespaces, nodes etc.).
Attacks
Now that we have covered the basic architecture of Kubernetes, we can have a look at possible attacks for Kubernetes. Below you can find the threat matrix from Microsoft developed for Kubernetes. The matrix shows the different MITRE ATT&CK tactics and how techniques to attack Kubernetes map to these tactics.
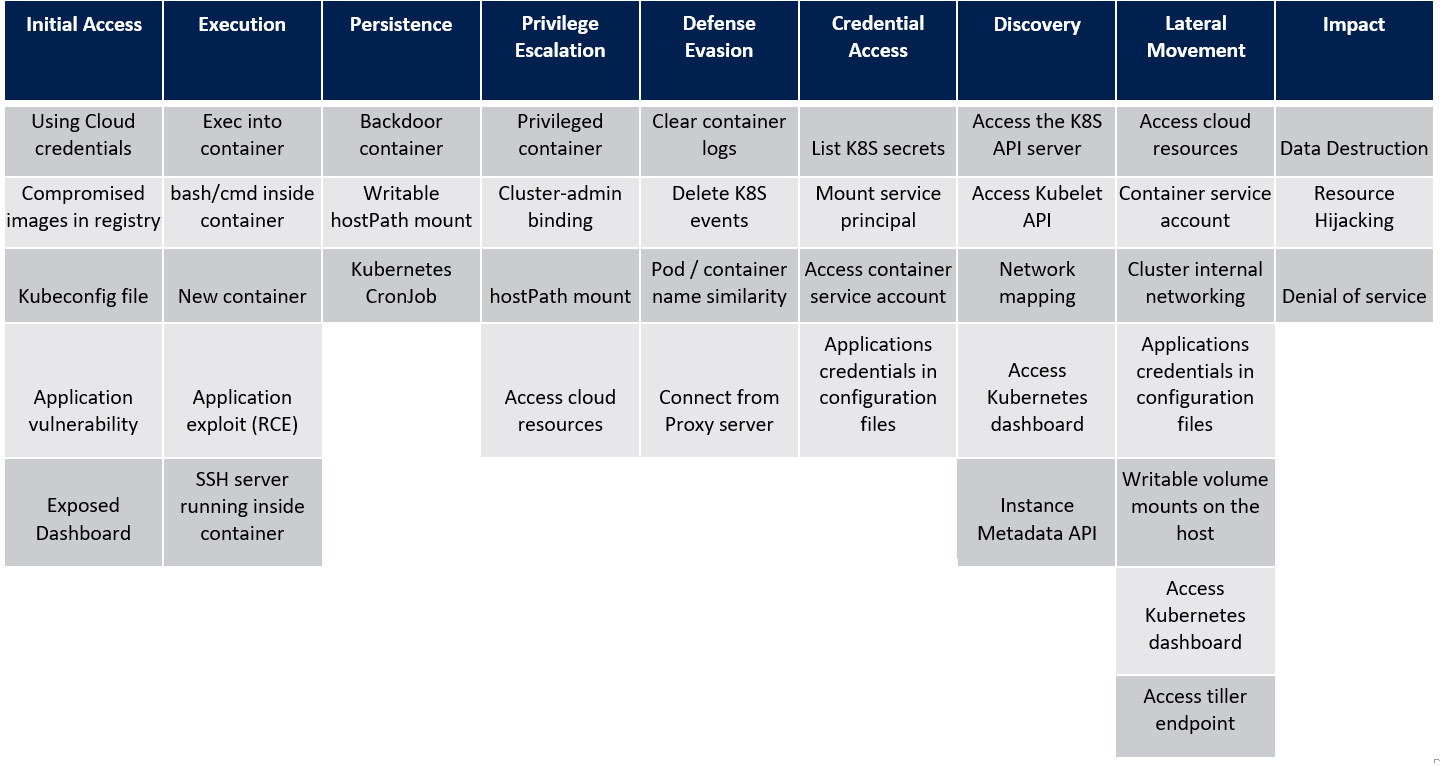
Image source: https://www.microsoft.com/en-us/security/blog/2020/04/02/attack-matrix-kubernetes/
After you gained an initial foothold on a cluster, you might want to laterally move to other pods and nodes (and namespaces) or elevate your privileges to gain access to cloud resources, until either your goal was reached, you cannot expand your access further, or you obtained control over the Kubernetes cluster altogether. In our upcoming blog article, we will explore Initial Access techniques and procedures and how attackers may use them to gain a foothold in the Kubernetes cluster.
Summary
In this article we went over the fundamentals and touched on different components and concepts relevant to gain a basic understanding of Kubernetes Architecture. We also scratched the surface on what could be possible from a perspective of offensive security. In the upcoming articles we will dive more deeply into enumeration and different attacks we can perform on a Kubernetes cluster.
For readers seeking to expand their knowledge, explore complex security challenges, or require assistance in securing their Kubernetes environments, don’t hesitate to contact the CovertSwarm team today. As specialists in cybersecurity, CovertSwarm is dedicated to helping organizations navigate the complexities of Kubernetes security.
Author: Maximilian Kleinke




